Noch mehr Fraktale
Seit meinem ersten Eintrag über meinen Fraktal-tweetenden Bot @AFractalADay, habe ich selbigen noch um ein paar Fraktale erweitert, die ich hier kurz festhalten möchte. Der ganze Code ist auf Github.
Chaotic Maps
Eine Quadratic Map ist eine Rekursionsgleichung mit einem quadratischen Term, also beispielsweise $$x_{i+1} = a_0 x^2 + a_1 x + a_2.$$ Das berühmteste Mitglied dieser Familie ist die Logistic-Map mit $a_0=1, a_1=r, a_2=0$, die chaotisches Verhalten für $3.56995 < r < 4$ zeigt. Aber leider ist sie nur eindimensional und ihr Attraktor deshalb nicht besonders hübsch.
Um visuell ansprechende Fraktale daraus zu erzeugen, brauchen wir also ein System aus zwei Rekursionsgleichungen, die wir als $x$- und $y$-Koordinaten betrachten können:
\begin{align} x_{i+1} &= a_{0} + a_{1} x + a_{2} x^2 + a_{3} x y + a_{4} y + a_{5} y^2\ y_{i+1} &= a_{6} + a_{7} x + a_{8} x^2 + a_{9} x y + a_{10} y + a_{11} y^2. \end{align}
Jetzt haben wir 12 freie Parameter, die einen riesigen Parameterraum aufspannen, in dem etwa 1.6% aller Möglichkeiten chaotisches Verhalten mit einem seltsamen Attraktor zeigen.

Chaotische Differentialgleichungssysteme
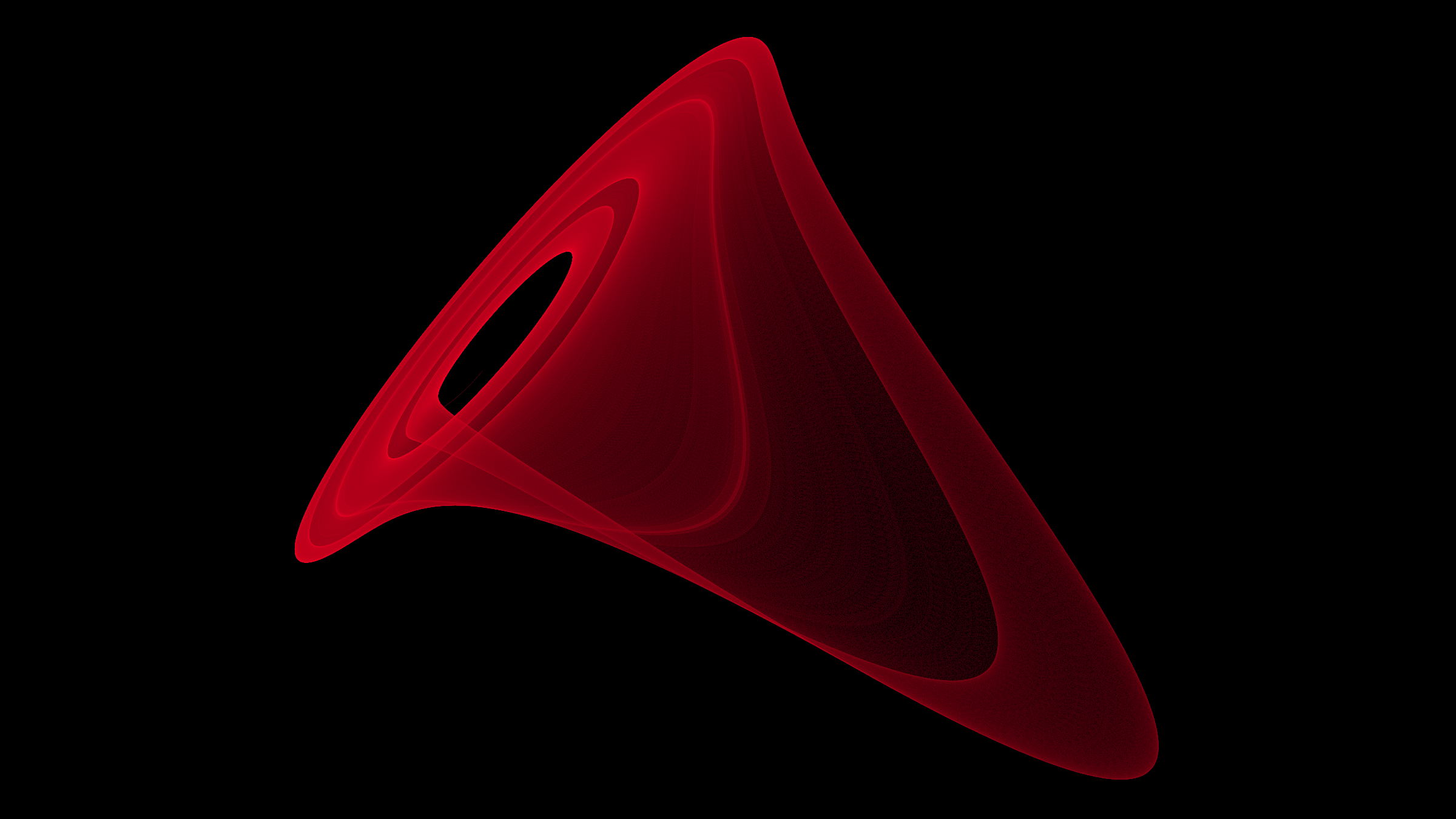
Ein echter Klassiker ist das Differentialgleichungssystem, das die Chaostheorie begründet hat und nach dem der Schmetterlingseffekt benannt ist [1, 2]. Für bestimmte Paramtersätze verlaufen die Bahnkurven entlang eines seltsamen Attraktors, dessen fraktale Dimension $\approx 2.06$ ist. Da der vollständige Attraktor somit in einer zweidimensionalen Projektion etwas langweilig aussieht, habe ich hier nur eine Trajektorie über kurze Zeit dargestellt.

Und es gibt eine ganze Menge weitere Differntialgleichungssysteme (und chaotic maps), die chaotische Attraktoren aufweisen. Deshalb zeige ich hier noch einen Rössler-Attraktor, der eine vereinfachte Version des Lorenz-Systems ist:
\begin{align} \frac{\mathrm{d}x}{\mathrm{d}t} &= -(y+z)\ \frac{\mathrm{d}y}{\mathrm{d}t} &= x + ay\ \frac{\mathrm{d}z}{\mathrm{d}t} &= b + xz - cz \end{align}
Und hier haben wir das Glück, dass auch seine Projektion sehr ansehnlich ist.
Ich persönlich frage mich, nun wie der Attraktor für das Doppelpendel aussieht. Es ist anscheinend kein Fraktal, aber es sieht dennoch ganz interessant aus:

Ising model
Das Ising Modell für Ferromagnetismus wird auch als Drosophila der statistischen Physik bezeichnet: Es ist ein einfaches Modell, dass einen Phasenübergang aufweist — Eisen verliert seine magnetischen Eigenschaften oberhalb der Curie-Temperatur.
Es besteht aus magnetischen Momenten, Spins, die gerne in die
gleiche Richtung zeigen wie ihre Nachbarn, aber durch hohe Temperatur
gestört werden. Oder etwas formaler: Die innere Energie $U$ wird durch
den Hamiltonian $\mathcal{H} = - \sum_{



{kind=link}