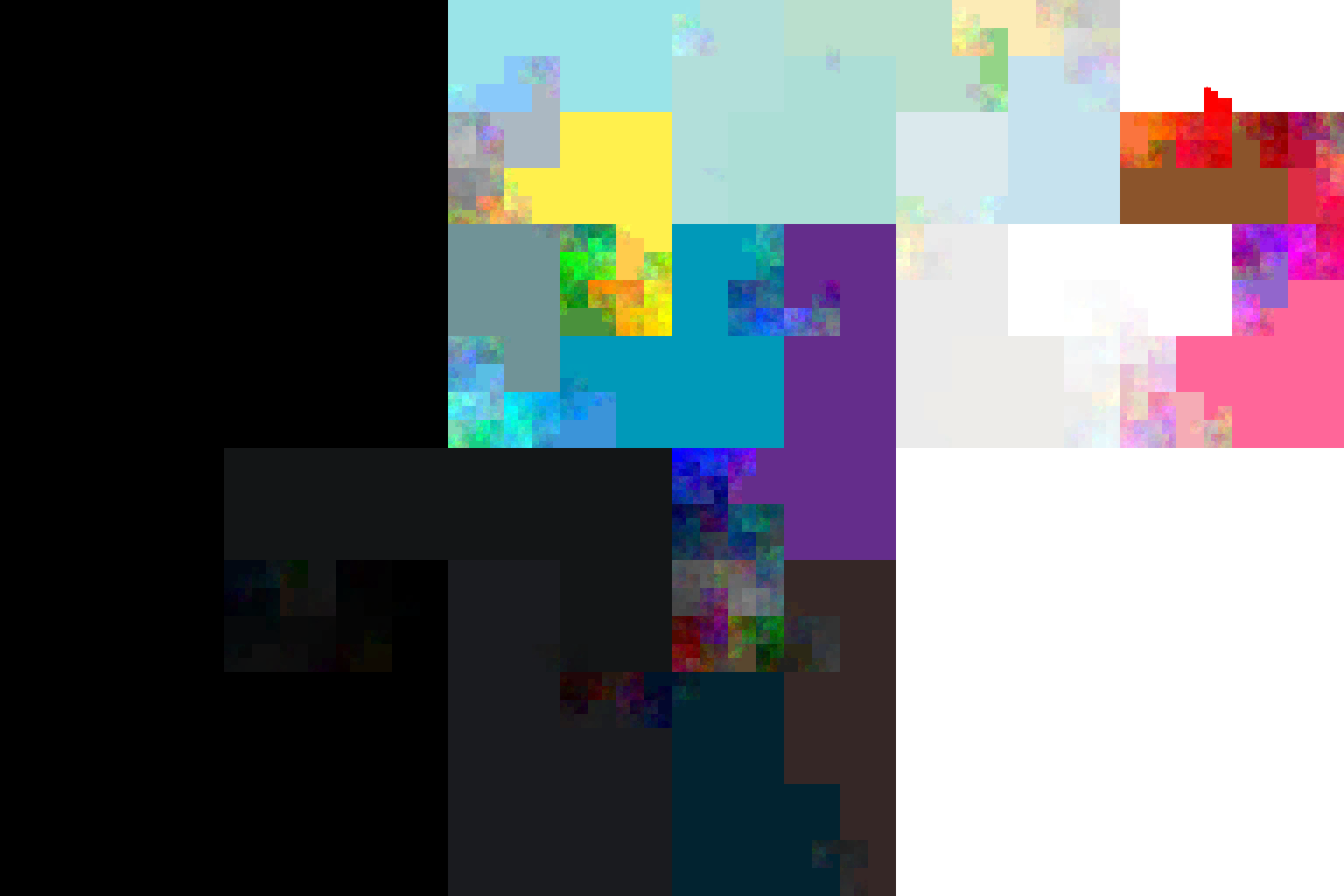Für ein Projekt habe ich Tweets von >8‘000‘000 Twitter-Usern eingesammelt.
Dabei fallen noch eine Reihe weiterer Daten an, wie die Profilhintergrundfarbe.
Es wäre eine Schande diese Daten einfach verkommen zu lassen, also habe ich
nach einer Möglichkeit gesucht diese Information ansprechend darzustellen,
was sich als weniger trivial herausgestellt hat, als ich ursprünglich angenommen
hatte: Im Idealfall sollten ähnliche Farben nahe beieinander liegen, allerdings
ist der RGB Farbraum ein dreidimensionaler Kubus, ein Bild aber nur zweidimensional,
sodass es keine
„richtige“ Art und Weise gibt, ähnliche Farben nebeneinander anzuordnen.
Ich habe mich hier dafür entschieden eine 2D Hilbert-Kurve
durch mein Bild zu legen und die Farben in der Reihenfolge zu zeichnen, in der
eine 3D Hilbert-Kurve ihnen im RGB-Kubus begegnet. Wenn man dann noch die beiden
Standardhintergrundfarben #F5F8FA und #C0DEED ignoriert, sieht das Ergebnis so aus.

Und dank der Python Pakete hilbertcurve und pypng ist der Code sogar ziemlich harmlos:
from math import ceil, sqrt, log2
from hilbertcurve.hilbertcurve import HilbertCurve
import png
"""
turn an RGB string like `#C0DEED` into a tuple of integers,
i.e., coordinates of the RGB cube
"""
def str2rgb(s):
s = s.strip("#")
return (int(s[0:2], 16), int(s[2:4], 16), int(s[4:6], 16))
"""
`color_histogram` is a dict mapping an rgb string like `#F5F8FA`
to the number of usages of this color
"""
def plot_background_colors(color_histogram, filename="colors.png"):
defaults = {"F5F8FA", "C0DEED"}
data = {str2rgb(rgb): d for rgb, d in color_histogram if rgb not in defaults}
# calculate the size of the resulting image
# for a 2D Hilbert curve, it mus be square with a width, which is a power of 2
num_pixels = sum(data.values())
min_width = ceil(sqrt(num_pixels))
exponent = ceil(log2(min_width))
width = 2**exponent
# output buffer for a width x width png, with 4 color values per pixel
buf = [[0 for _ in range(4 * width)] for _ in range(width)]
hc2 = HilbertCurve(exponent, 2)
# there are 256 = 2^8 values in each direction of the RGB cube
hc3 = HilbertCurve(8, 3)
sorted_rgbs = sorted(data.keys(), key=lambda x: hc3.distance_from_point(x))
idx = 0
for rgb in sorted_rgbs:
for _ in range(data[rgb]):
# get the coordinate of the next pixel
x, y = hc2.point_from_distance(idx)
# assign the RGBA values to the pixel
buf[x][4 * y] = rgb[0]
buf[x][4 * y + 1] = rgb[1]
buf[x][4 * y + 2] = rgb[2]
buf[x][4 * y + 3] = 255
idx += 1
png.from_array(buf, 'RGBA').save(filename)
Das Histogram, das als Input benötigt wird war in meinem Fall nur eine SQL Query entfernt:
SELECT profile_background_color, COUNT(profile_background_color) FROM users
GROUP BY profile_background_color;