Relative Neighborhood Graph
Zu jedem Zeitpunkt ist im obigen Video ein Relative Neighborhood Graph (RNG) zu sehen. Der RNG verbindet Knoten miteinander, die nahe beieinander sind. Für die Knotenmenge $V$ muss also eine Metrik definiert sein, sodass eine Distanz $d_{ij}$ zwischen zwei Knoten definiert ist. Dann verbindet der RNG alle Knoten, die die Bedingung $$ d_{ij} \le \max(d_{ik}, d_{kj}) \quad \forall k \in V\setminus{i, j} $$ erfüllen.
Dementsprechend simpel kann man einen RNG erzeugen.
import random
import networkx as nx
import matplotlib.pyplot as plt
def dist(n1, n2):
"""Euclidean distance"""
return ((n1[0] - n2[0])**2 + (n1[1] - n2[1])**2)**0.5
def rng(G):
"""Insert edges according to the RNG rules into the graph G"""
for c1 in G.nodes():
for c2 in G.nodes():
d = dist(c1, c2)
for possible_blocker in G.nodes():
distToC1 = dist(possible_blocker, c1)
distToC2 = dist(possible_blocker, c2)
if distToC1 < d and distToC2 < d:
# this node is in the lune and blocks
break
else:
G.add_edge(c1, c2)
if __name__ == "__main__":
# generate some random coordinates
coordinates = [(random.random(),random.random()) for _ in range(100)]
G = nx.Graph()
for x, y in coordinates:
G.add_node((x, y), x=x, y=y)
rng(G)
# draw the graph G
pos = {n: (n[0], n[1]) for n in G.nodes()}
nx.draw_networkx_nodes(G, pos=pos, node_shape="o")
nx.draw_networkx_edges(G, pos=pos)
plt.show()
Interessanterweise tauchen alle Kanten des RNG auch in der Delaunay Triangulation der gleichen Knotenmenge auf. Dies kann man nutzen, um RNGs in $\mathcal{O}(N \log N)$ zu konstruieren.
Meiner persönlichen Meinung nach, bildet der RNG mit dem Verhältnis von Knoten zu Kanten ein ästhetisches Optimum.
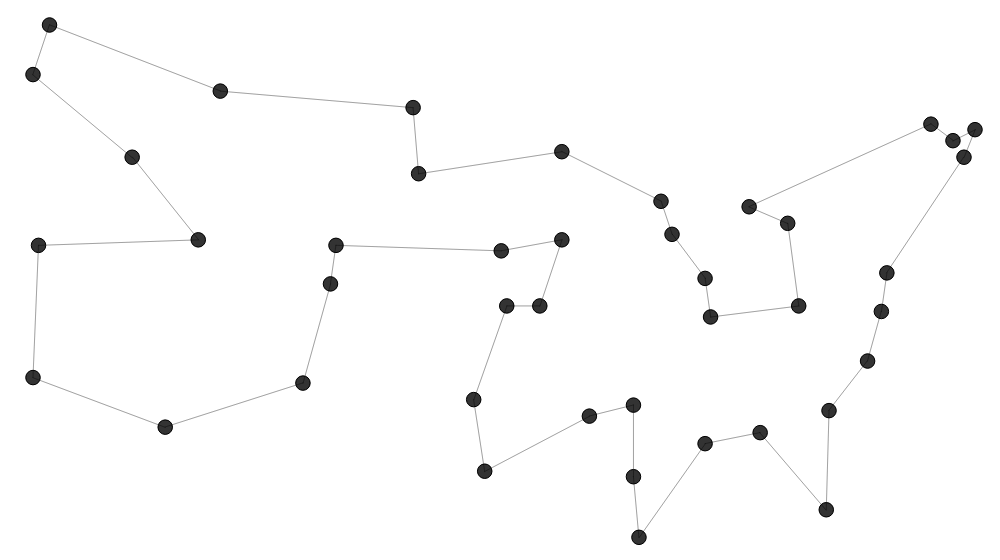
 Das sind 42 Hauptstädte der Vereinigten Staaten von Amerika und Washington,
Das sind 42 Hauptstädte der Vereinigten Staaten von Amerika und Washington, 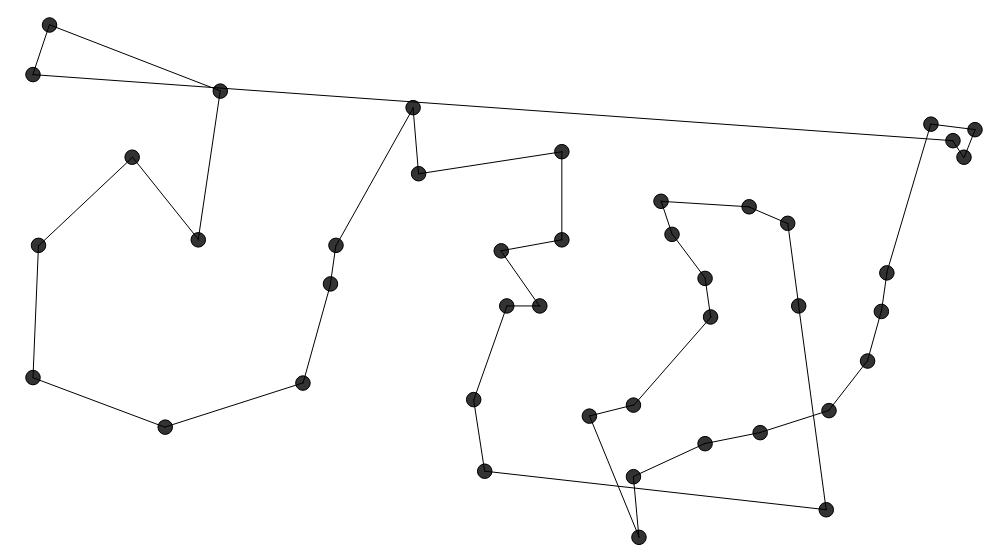 Die Nearest Neighbor Heuristik ($\mathcal{O}(N^2)$) startet bei einer zufälligen Stadt und wählt
als nächste Stadt immer die Stadt, die am nächsten an der aktuellen Stadt ist und
noch nicht besucht wurde.
Die Nearest Neighbor Heuristik ($\mathcal{O}(N^2)$) startet bei einer zufälligen Stadt und wählt
als nächste Stadt immer die Stadt, die am nächsten an der aktuellen Stadt ist und
noch nicht besucht wurde.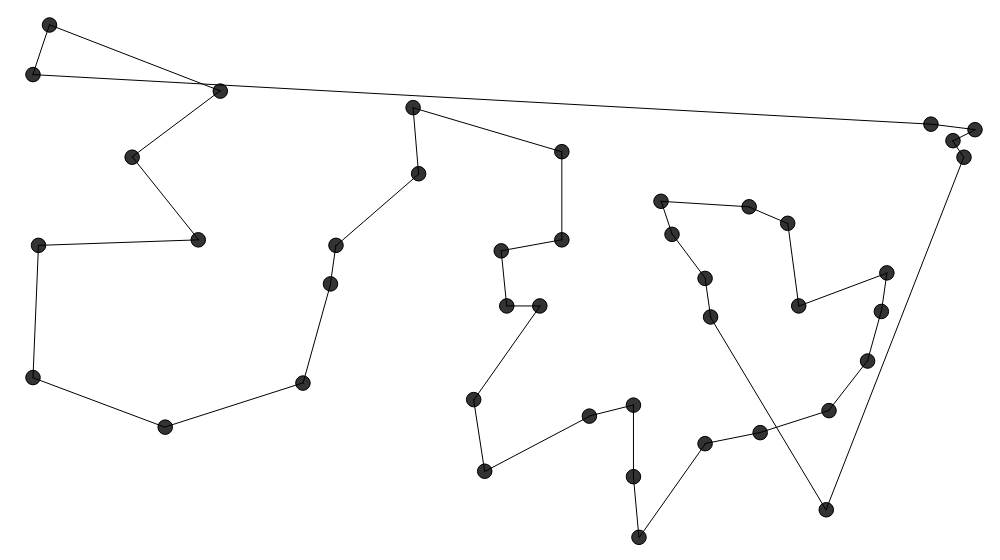 Diese Heuristik ($\mathcal{O}(N^2 \log N)$) ist ähnlich zu
Diese Heuristik ($\mathcal{O}(N^2 \log N)$) ist ähnlich zu 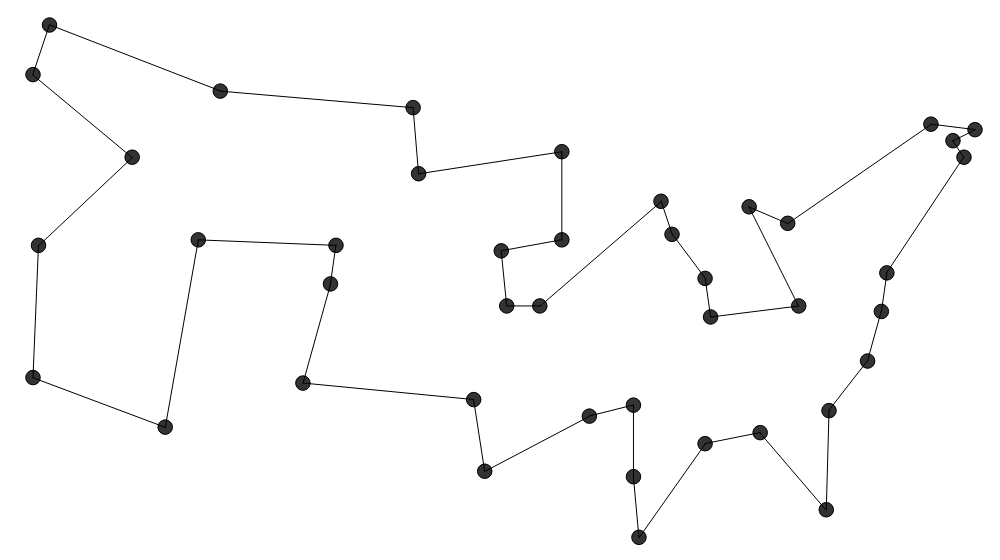 Farthest Insertion ($\mathcal{O}(N^3)$) startet bei einer zufälligen Stadt und fügt dann die Stadt,
die am weitesten von der aktuellen Tour entfernt ist an der Stelle in die Tour,
die dafür sorgt, dass die Tour möglichst kurz bleibt.
Farthest Insertion ($\mathcal{O}(N^3)$) startet bei einer zufälligen Stadt und fügt dann die Stadt,
die am weitesten von der aktuellen Tour entfernt ist an der Stelle in die Tour,
die dafür sorgt, dass die Tour möglichst kurz bleibt.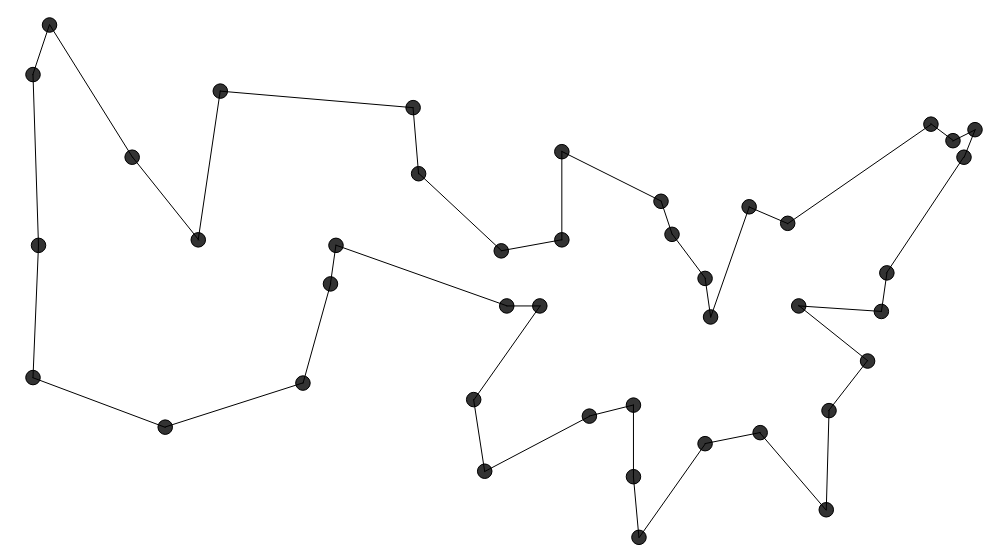 Two-Opt beginnt mit einer beliebigen Tour, die bspw. durch eine der obigen
Heuristken erstellt wurde und verbessert sie, indem sie zwei Verbindungen nimmt
und die Endpunkte über Kreuz austauscht, wenn die Tour dadurch verbunden bleibt
und kürzer wird.
Two-Opt beginnt mit einer beliebigen Tour, die bspw. durch eine der obigen
Heuristken erstellt wurde und verbessert sie, indem sie zwei Verbindungen nimmt
und die Endpunkte über Kreuz austauscht, wenn die Tour dadurch verbunden bleibt
und kürzer wird.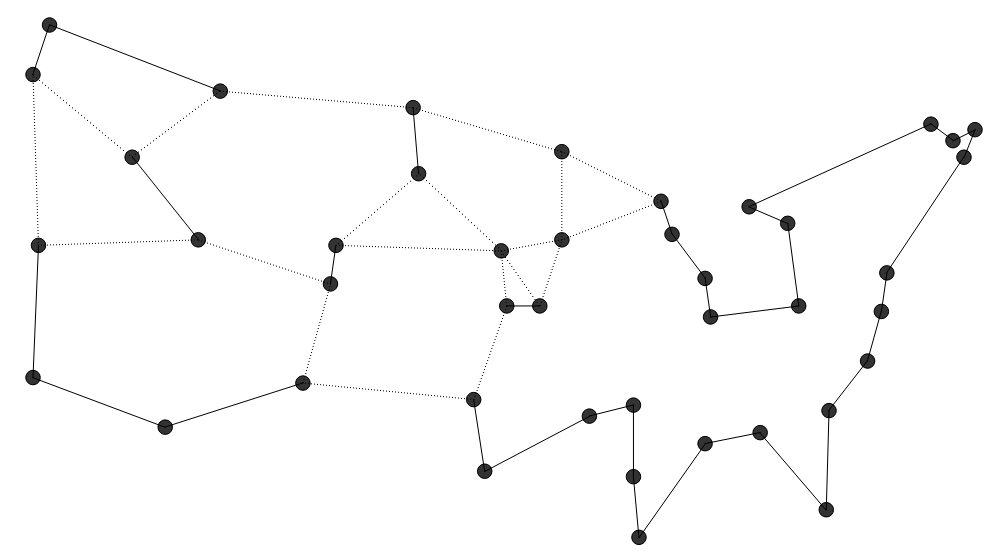 Lineare Programmierung (
Lineare Programmierung (